




在心理学考研复习的过程中,很多同学对标准差和标准误总是傻傻分不清,要了解标准误和标准差的区别,首先要回顾一下以下这三种分布,相信大家在复习时都接触过,现在快跟着文都比邻小编重新学习一下吧。
三种分布
1. 总体分布
我们所要研究的所有对象组成的集合叫做总体。而总体中每一个随机变量X的取值概率形成的分布就是总体分布。如研究对象是一个城市所有居民的身高,那这个城市所有市民的身高就会形成如下总体分布:
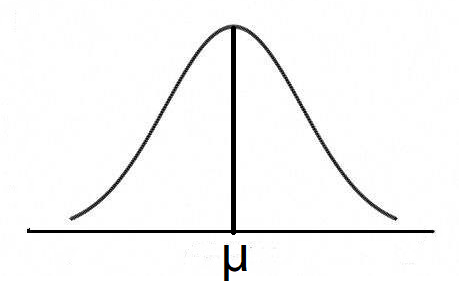
在这个分布里,横坐标上的X代表这个城市每个居民的身高,μ为总体的平均身高。
2. 样本分布
从总体中随机抽样的一部分个体组成了样本,这个样本里的每一个随机变量X的取值概率形成的分布就是这个样本的分布。比如从一个城市中随机抽取200人作为一个样本,他们每个人的身高形成了如下样本分布:
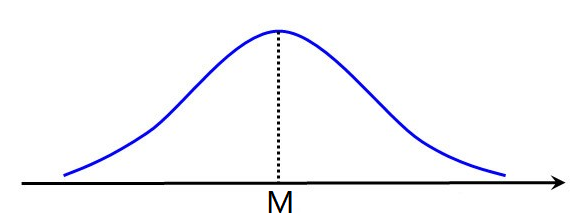
在这个分布里,横坐标上的x代表这个200人样本里每个人的身高,M为样本的平均身高。
综上所述(前两种分布)
①在形态上,身高的总体分布和样本分布都为正态分布,除了离散程度不一样以外,其他的部分看起来都差不多。
②这两个分布的对象虽然都是城市居民的身高,但实际上一个是总体的分布,一个是随机抽取的样本分布;一个横坐标代表整个城市每个居民的身高,一个横坐标只代表随机抽取的这200人的身高。
3. 样本均值分布
样本均值的分布也叫样本均值的抽样分布,即从一个总体中随机抽取无数个样本,每个样本的均值形成的分布。在样本均值分布里,横坐标代表的不再是每个居民的身高,而是每个样本中居民身高的均值。
在上面的例子中,一个城市所有居民的身高形成了总体分布,从中随机抽取200人的身高形成了一个样本分布。如果我们继续抽样,依然以200为样本容量,从总体中随机抽取无数个这样的样本,每个样本都算出均值,我们就会发现,这些均值也形成了一个正态分布,这就是样本均值分布。根据中心极-限定理,样本均值分布的数学期望(均值)为总体均值μ。
样本均值分布的特点
①样本均值分布横坐标上的每个X代表所有样本中身高的均值,而不是每个居民的身高。
②无论原总体的分布是不是正态分布,当样本容量大于等于30时,样本均值分布都为正态分布;当样本容量小于30时,样本均值分布趋于正态分布。
学习完以上三种分布并了解了它们之间的区别之后,我们就可以对标准差和标准误进行区分了。
标准差
总体标准差公式:
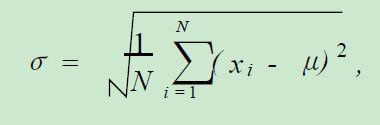
其中xi是总体里的每一个居民的身高,μ是总体均值,N为总体容量。
样本标准差公式:
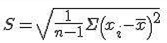
其中xi是样本里的每一个居民的身高,`x是样本均值,n为样本容量。
注意
标准差只存在于总体分布和样本分布里,用来衡量总体和样本的离散程度。如果要衡量样本均值分布的离散程度,就需要用到标准误的概念。
标准误
标准误公式:
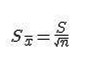
标准误与标准差的计算公式非常像,但这是两个完全不同的概念。
标准误是样本统计量的标准差,在上面三个分布中,只有样本均值分布中才有标准误的概念,它用来衡量样本均值这个样本统计量的离散程度,也代表样本平均数和总体平均数之间的误差。在计算标准误时,需要使用到样本标准差。
总结
1. 标准差只在总体和样本中才有,分为总体标准差和样本标准差,计算方式一样,但是字母用大小写区分开。
2. 标准差衡量的是总体或样本中具体分数的离散程度,比如身高。
3. 标准误只在样本均值分布中才有,计算公式和标准差很像,但概念完全不一样。
4. 标准误衡量的是样本统计量(平均值)的离散程度,比如身高的均值。
以上就是文都比邻小编为大家准备的心理学考研之心理统计学:标准差和标准误的区别。为方便大家备考,我们还为大家准备了更多的考研信息,比如备考指导、参考书目、历年真题等,想要获取更多考研信息的小伙伴可以关注文都比邻考研网哦!

 关注文都比邻微信
关注文都比邻微信















